
Vector Database on S3 only
little journey into Vector Databases, RAG and small embedding models
This prototype of a RAG system is running on AWS Lambda without any Database, only S3.
So there are no running costs of this serverless solution. Made with lanceDB 💓 .
The service consists of two lambda functions. The first one takes a search query and returns a vector embedding. The second lambda takes the embedding of the first and does the semantic search.
Before starting you need to vectorize your documents with lanceDB (well documented on their website). I performed this process using three different chunk sizes: 100, 200, and 400 characters. After vectorizing the documents, upload the lanceDB files to an S3 bucket (e.g. by using the command `aws s3 sync LOCAL-FOLDER S3://BUCKET`.)
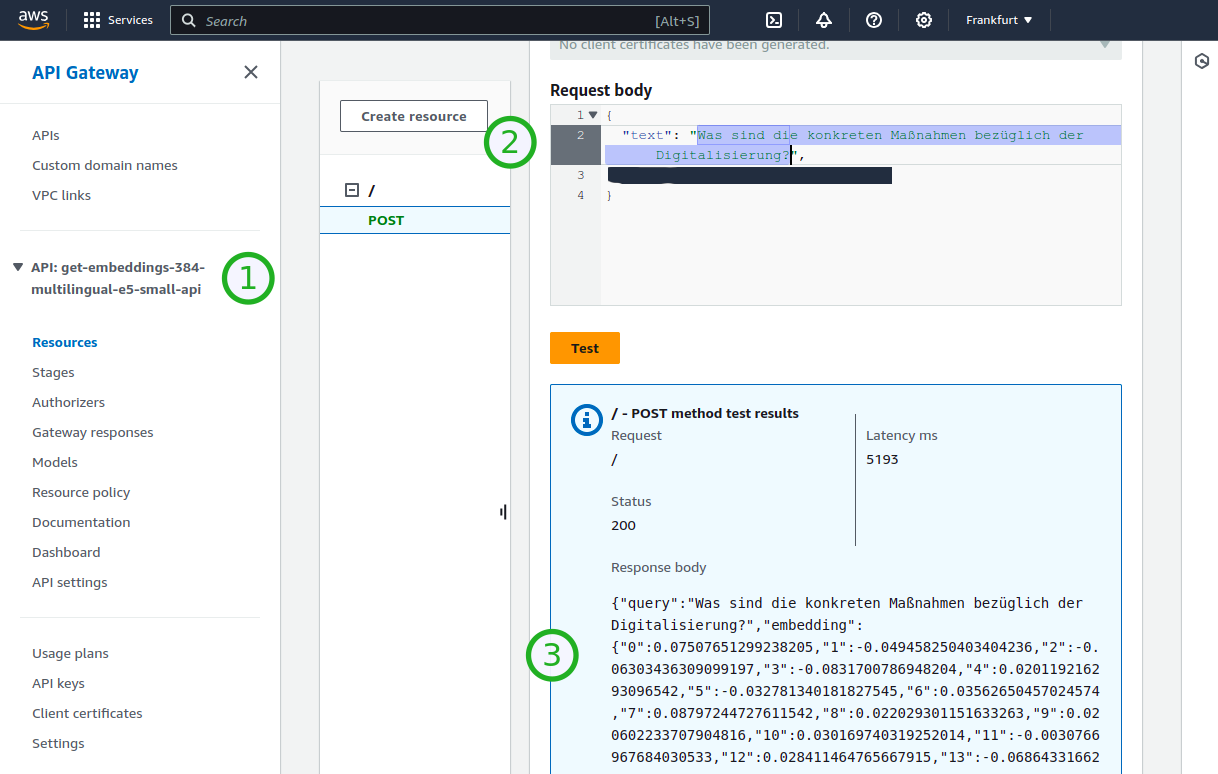
Step 1: Get embedding.
To reduce memory and RAM usage, the deployment utilizes a small model (e5-small multilingual) to obtain the embedding vector. This model is only 470 MB in size and is deployed within the container, loading into RAM during execution. For a real application, it may be more efficient and much faster to execute this step on the client machine (ONNX Models can even be run in the browser 💓). The Lambda Function is limited to a maximum of 1024 MB of RAM. So no big and expensive machines needed.
Screenshot showing one way to get the embedding (3) of a text sentence (2) via an API-Gateway Endpoint (1) in AWS Console.
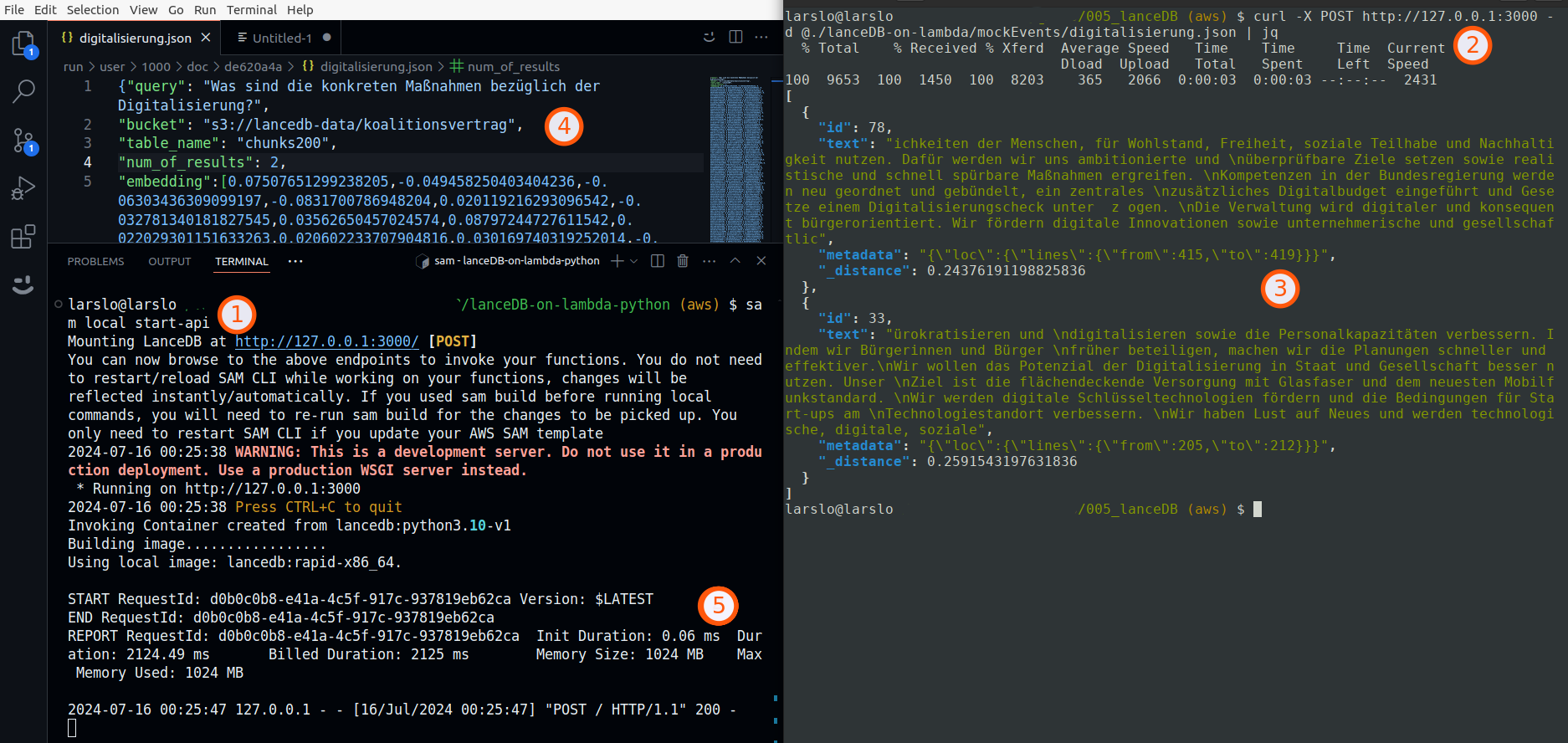
Step 2: Semantic Search
Using the Germans government’s “Koalitionsvertrag” as a source and the question “What are the specific measures regarding digitalization?” we get some promising results.
Screenshot showing the usage and results of a semantic search.
(1) Spin up a local lambda container
(2) Post an event to the endpoint, e.g.
{
"query": "What are the specific measures regarding digitalization?",
"bucket": "s3://lancedb-data/koalitionsvertrag",
"table_name": "chunks200",
"num_of_results": 4,
"embedding":[0.06438450515270233,-0.03899127617478371,...(384)]
}
(3) The results
(4) Using S3 file system (not a database) to do semantic search.
(5) Its not quick but efficient in memory usage.
And since it’s a multilingual model, we can query the document in other languages, yielding slightly different results.
The following screenshot shows the English results queried via the AWS Console.

Amazed by the capabilities of semantic search with simple transformer models.
larslo
![]()
AWS Lambda based Notifications
A simple notification service sending an email when a webpage changes for almost no costs.
It can be used to keep informed about very specific topics, by watching single webpages. With this setup you can to watch multiple websites with the same lambda function.
"""
Outline:
- a lambda function that extracts the text contents from a single webpage
- its saves the text contents as a document in a S3 bucket.
- the extraction is done with pythons beautifulsoup library.
- it compares the current text contents with the previous text contents and sends an email if there is a change.
- when the content changed, update the previous text contents in the S3 bucket
"""
import urllib.request
from bs4 import BeautifulSoup
import json
import difflib
from typing import List
bucketName = "changes-in-websites"
"""
use the ARN of the SNS topic (Simple Notification Service) to send emails
"""
snsArn = "[arn:aws:sns]"
"""
mock event, use EventBrigde or similar to send such a event
"""
# event = {
# "url": "https://website-to-check.com/topic",
# "classSelektor":"class-of-main-content",
# "domNodeType": "div|main|section|article",
# "tags": "key1=value1&key2=value2", # optional, might be useful for tagging S3 docs or cloudwatch logs
# }
"""
lets make a S3 key from url, replace all special url characters with underscore
"""
def make_bucket_key_from_url(url):
key = url.replace(".", "_")
key = key.replace("/", "_")
key = key.replace(":", "_")
return key
"""
get the previous text from the s3 bucket
"""
def get_previous_text_from_s3(bucketName, key):
s3 = boto3.resource("s3")
try:
response = s3.meta.client.get_object(Bucket=bucketName, Key=key)
previousText = response['Body'].read().decode('utf-8')
return previousText
except:
return ''
"""
publish a message to the SNS topic
"""
def send_email(url: str, changes: List[str], subject: str) -> None:
sns = boto3.client('sns')
message = f"{url}\n{'\n'.join(changes[:20])}"
try:
response = sns.publish(
TopicArn = snsArn,
Message = message,
Subject=subject
)
except Exception as e:
print(f"An error occurred: {e}")
"""
the lambda handler
"""
def lambda_handler(event, context):
url = event['url']
# fail early when url is not set
if url == None:
return {
"statusCode": 400,
"body": json.dumps({
"message": "url is not set"
}),
}
bucketKey = make_bucket_key_from_url(url)
selector = event['classSelektor']
try:
res = urllib.request.urlopen(urllib.request.Request(
url=url,
headers={
'User-Agent': 'Mozilla/5.0'
},
method='GET'
),
timeout=10
)
except urllib.error.URLError as e:
send_email(url, ["url not reachable", url, e.reason], "url not reachable "+url)
return {
"statusCode": 400,
"body": {
"message": "url " + url +" is not reachable"
},
}
# check if response status code is 200
if(res.getcode() != 200):
subject = "website response not 200"
send_email(url, [subject, url, res.getcode()], subject)
return {
"statusCode": 400,
"body": {
"message": "url " + url + " " + subject,
},
}
response = res.read()
# todo what if page has other encoding
soup = BeautifulSoup(response, 'html.parser')
# check if selector is set and not empty
if (selector == None or selector == ""):
text = soup.get_text()
else:
domNodeType = 'div'
if(event['domNodeType']!= None and event['domNodeType']!= ""):
domNodeType = event['domNodeType']
text = soup.find(domNodeType, {"class": selector}).get_text()
previousText = get_previous_text_from_s3(bucketName, bucketKey)
s3 = boto3.resource("s3")
# no former entry for this URL, save the current text
if(previousText==""):
tags = ''
if(event['tags']!= None and event['tags']!= ""):
tags = event['tags']
s3.Bucket(bucketName).put_object(
Key=bucketKey,
Body=text,
ContentType='string',
Tagging=tags
)
send_email(url, ["Now watching: " + url + "\n\n\n" + text], "Now watching: "+url)
return {
"statusCode": 200,
"body": json.dumps({
"message": "saved text of URL: " + url,
"bucket" : bucketName,
"key" : bucketKey,
})
}
# compare current and previous text
changesGenerator = difflib.context_diff(previousText.splitlines(), text.splitlines(), fromfile='previous', tofile='current')
changes = list(changesGenerator)
# the simplest form: if there are changes, send an email, but not the changes itself
if(len(changes) > 0):
tags = ''
if(event['tags']!= None and event['tags']!= ""):
tags = event['tags']
changes.insert(0, "website changed " + url + "\n\n\n")
s3.Bucket(bucketName).put_object(
Key=bucketKey,
Body=text,
ContentType='string',
Tagging=tags
)
send_email(url, changes, "changes in url " + url)
# a return might be useful for debugging, testing the lambda function
return {
"statusCode": 200,
"body": {
"message": "updated text of URL: " + url,
"bucket" : bucketName,
"key" : bucketKey,
"num of changes": len(changes),
"changes 10 lines": "\n".join(changes[:10])
}
}
![]()